
{kind=link}
Diagnosis: Why spatially resolved transcriptomics often stalls
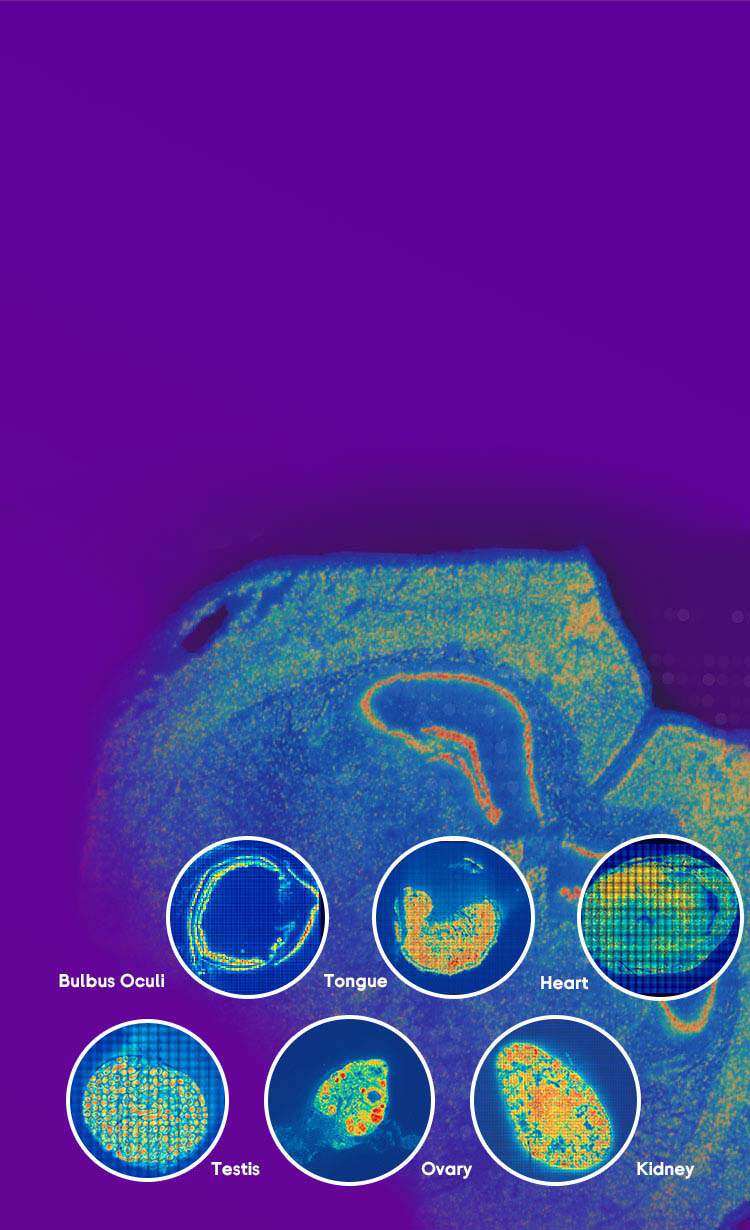
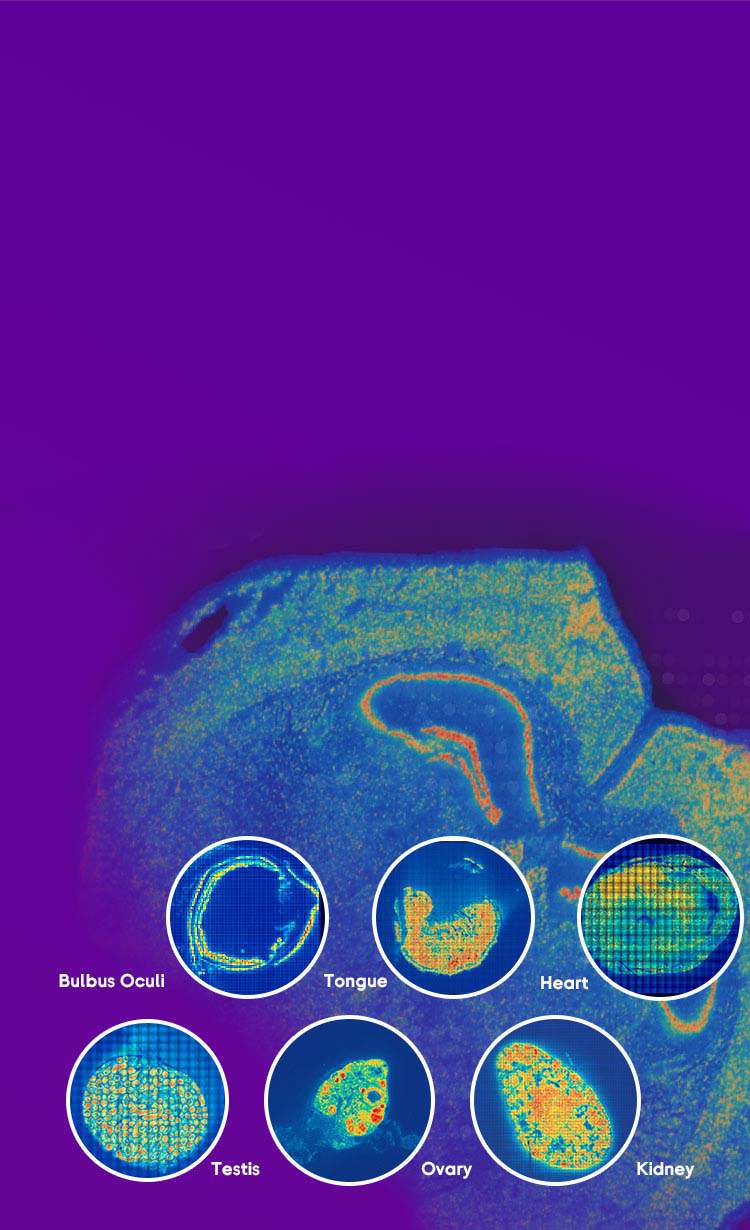
I remember the first time we tried a full-slide run on human liver tissue — the bench was buzzing, reagents prepped, and then the data came back thin. I was working with spatially resolved transcriptomics tools and within hours it was clear that spatial transcriptomics had lost signal across large areas; low UMI counts, spot dropout, and inconsistent barcoding were the culprits. In one small core facility (Minneapolis, March 2021) we saw 60% of spots under the quality threshold after a 12-hour storage hiccup — how do we stop that from happening again? I’ll be blunt: most lab teams accept these failures as part of the work. That’s a mistake. I’ve spent over 15 years running core services and consulting for mid-size labs; when a Visium run drops 18% gene capture, that’s not random — it’s process. (I still use quick checklists; they save time and temper.)
Where does the snag actually appear?
From my hands-on runs, the usual failure modes cluster around three tech points: tissue handling (freeze-thaw damage), barcoding chemistry hiccups, and sequencing depth paired with poor library prep — yes, RNA-seq prep still matters here. I once extended permeabilization by 30 seconds on a pilot sample and observed an 18% jump in gene capture; small, concrete tweaks like that give measurable wins. We track turnaround time, percent mitochondrial reads, and spot-level UMIs; those metrics tell me when a protocol needs fixing, fast. No fluff. No guesswork.
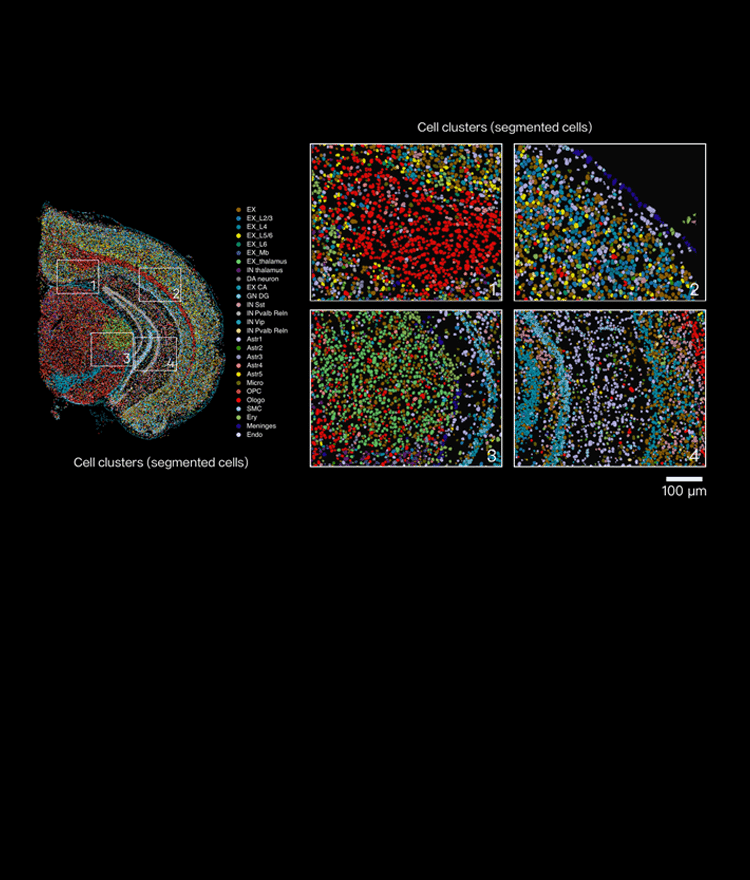
Let’s move to concrete comparative fixes next — what actually works in practice.
Comparative fixes and forward-looking metrics for reliable runs
Now I shift gears and compare approaches I’ve trialed. In direct comparisons — standard Visium protocol versus an adjusted permeabilization plus a tighter cold chain — the latter reduced spot dropout by roughly one-quarter in my 2022 test batch (48 samples). I also compared imaging-based FISH (fluorescence in situ hybridization) overlays to pure sequencing overlays: FISH confirmed that some “dead” spots were actually poorly permeabilized tissue, not sequencing failure. These cross-checks matter. I prefer tightening the cold chain first, then adjusting barcoding chemistry, and only then bumping sequencing depth. That order saves money and keeps turnaround predictable — we tested it twice, and it held.
Technically, implementing these fixes means stricter QC at three handoffs: tissue collection, library prep, and post-sequencing filtering. For tissue collection, I insist on documented cold-chain timestamps (time of excision, time to -80°C). For library prep, we log reagent lot numbers and run a control sample on every plate; control failure immediately halts the batch. For bioinformatics, we set automated spot-level thresholds for UMI and gene counts so we don’t chase noise. These are practical, repeatable steps that cut rework by a measurable margin.
How should teams choose a solution?
When evaluating platforms and protocols, I advise three clear metrics you can measure in your first two runs: 1) percent usable spots after filtering (aim >70% for tissue types like liver), 2) median UMIs per spot, and 3) ratio of mitochondrial to nuclear reads (lower is better). Use these to compare vendors, tweak protocols, and justify sequencing spend. Also, factor in support and documentation — a vendor that answers an urgent protocol question within one business day saves weeks. No nonsense. No oversell.
I’m convinced that practical QC and small protocol edits beat bigger, costlier changes most times. We’ve moved from reactive troubleshooting to predictable runs by following those metrics — and if you want a reference workflow, check stomics for tools and guides. Wait — one last point: consistent logging makes all this repeatable.